Intercoder Reliability

What is intercoder reliability in qualitative research?
Intercoder reliability (ICR) is a measurement of how much researchers agree when coding the same data set. It is often used in content analysis to test the consistency and validity of the initial codebook. In short, it helps show that multiple researchers are coming to the same coding results.
Said another way: intercoder reliability “ensures that you yourself are reliably interpreting a code in the same way across time, or that you can rely on your colleagues to use it in the same way.” (Richards, 2009)
Ultimately, ICR measures the consistency of coding results in order to improve the validity of the study overall.
What is intra-coder reliability?
In contrast to intercoder reliability, intra-coder reliability is when you measure the consistency of coding within a single researcher’s coding. However, we keep the focus on intercoder reliability for the purpose of this article.
Why reliability matters in qualitative research?
ICR, also referred to as intercoder agreement or inter-rater reliability, is just one of several ways to improve reliability in qualitative research. Reliability itself refers to whether or not a study provides consistent results that can be replicated by other researchers.
The ability to reproduce a study is also called transferability, which is “addressed by providing a detailed account of the study context through a rich description in the presentation of results.” (Shenton, 2004) For example, in ICR, this means publishing how the process unfolded and quantifying the results in the final write-up.
Deconstructing the purpose of reliability as a mental model:
Data collection and analysis aim to provide answers to research questions in a study.
The data needs to serve as a reliable tool to derive results and draw conclusions.
That means researchers need to make sure that this data is unbiased and that it means the same thing to everyone who uses it.
To establish trust in the data, ICR (as one option) measures reliability in an empirical way.
When should you use intercoder reliability?
Intercoder reliability can be used when multiple analysts code the same data. To reduce bias from the person who created the coding system, Krippendorf (2004) suggests having at least three analysts in total. One researcher designs the codebook. Then, at least two others use it to code samples of the data.
As a type of researcher triangulation, the researchers compare the results of the independent coders to evaluate the reliability of the initial codebook. The degree of intercoder agreement then acts like a stress test for the transferability and trustworthiness of the research results.
For example, reliability is particularly important in content analysis where researchers interpret and then assign meaning to language. The process itself is largely subjective and ICR is one way to allay skepticism that may arise in other researchers.
It is also important to note that achieving intercoder reliability is not appropriate for all qualitative research settings. Here is what to consider when deciding whether or not to measure intercoder reliability.
Use intercoder reliability when:
You’re running a study where you want multiple researchers to interpret data in a similar way.
You want your data to be coded in a consistent and standardized manner.
A publication requires that you calculate intercoder reliability.
Do not use intercoder reliability when:
You want to utilize the diverse perspectives of multiple researchers.
You want to discover new findings and be surprised by how different people can code the same passage in different ways.
You’re doing an exploratory study.
You will find consensus coding or split coding is an ideal alternative to use in more exploratory studies.
Why is Intercoder Reliability Important?
Continuing with transferability, researchers use intercoder reliability to ensure that they code the data consistently. Measuring this consistency helps balance the subjectivity of the coding process itself.
Another benefit is that this technique lets you confidently divide and conquer large data sets. For instance, once you know that your team is able to code relatively consistently, you can split the work, have each researcher take a different portion of the data, and know that they will code it in a consistent manner.
Intercoder Reliability in Content Analysis
ICR is not specific to any single research approach. However, as mentioned, intercoder reliability is crucial in content analysis because it tends to be a subjective and interpretive process.
On subjectivity, Potter and Levine-Donnerstein (1997) explain that content analysis involves coding both manifest content (what’s visible on the surface of the text) and latent content (hidden meaning beneath the surface). Especially for latent content, coders rely on their own interpretations based on their personal viewpoints, which highlights the importance of ensuring that their judgments are shared across coders.
Content analysis also tends to work on large samples of textual data. That means intercoder reliability is also useful in dividing up work among different coders to save time. When there's a high level of intercoder agreement, you can cover more ground and trust that all coders are coding in the same way.
[Related readings: The Practical Guide to Qualitative Content Analysis]
How Do You Calculate Reliability?
Choose which measurement to use.
There are many different measures for calculating ICR. Ideally, researchers would all agree on the “best” measurement to use but this remains an ongoing topic of debate [1]. With that being said, here are some examples of the most frequently used options along with pros and cons of each:
Percent agreement
Percent agreement is a straightforward method of measuring inter-rater reliability that calculates the percentage of times that two or more coders agree on a given observation or measurement. It doesn't take into account the degree of agreement and doesn’t factor in that coders may agree by chance. The percentage represents how often coders agree on the same code out of the total number of units. In content analysis, for example, that could be how many words or sentences are coded the same.
Benefits:
Not time-intensive.
Fairly simple compared to other methods.
Helpful for giving simple estimates for ICR.
Limitations - Should not be used alone to calculate intercoder reliability because:
Doesn’t take into account that coders may agree by chance.
Doesn't give specific information on where the coders disagree.
It is considered too liberal to use as the sole measurement of reliability.
Formula:
(Number of agreements / Total number of units of analysis) x 100
Holsti's method
Holsti’s method is a way to measure how much coders agree with each other when they are not coding the exact same sections of the data. If they coded the same sections, it would be equivalent to percent agreement. Like percent agreement, this method also does not consider the possibility of the coders agreeing by chance.
Benefits:
Another time-efficient method of ICR.
Provides simple estimates for ICR.
Allows researchers to cover more data by coding different sections.
Limitations:
It assumes that each coder works independently, which might not always be true.
Doesn’t consider that coders may agree by chance.
Is not generally considered reliable or accurate enough to be the sole measure of ICR.
Formula:
a = Number of agreements on items with category presence
b = Number of agreements on items with category absence
c = Number of disagreements on items with category presence
d = Number of disagreements on items with category absence
% Agreement = ((a+b)/(a+b+c+d)) x 100
Scott's pi (p)
Scott's pi (p) is commonly used in content analysis where researchers want to simultaneously categorize different types of content such as speeches, journals, news articles, and more. However, it doesn’t measure if different coders assign values differently across the coding categories and assumes coders distributed values equally across them by chance. The controversy with this technique is that if values are not distributed equally, it creates a bias and renders inaccurate measurements.
Benefits:
Does account for chance agreement.
Considered a more reliable measure of ICR than percent agreement or Holsti’s method.
Accounts for the number of categories and the distribution of values across them.
Limitations:
Only suitable for categorical data (data sorted into groups or categories e.g. race, gender, age ranges, and education levels).
Doesn’t account for how each coder distributes their own values across categories.
It also assumes that each coder works independently, which might not always be true.
Can only be used by two coders that analyze nominal-level variables, like the data (or content) used in content analysis.
Formula:
p = Proportion of observed agreements
pe = Expected proportion of agreements by chance
Pi = (p-pe) / (1-pe)
Cohen's kappa (k)
Cohen's kappa and Scott's pi are similar measures that assess how well different coders agree on categorizing content. The main difference between Cohen's kappa and Scott's pi is how they calculate chance agreement. Cohen's kappa takes into account differences in the distribution of values across categories for different coders, while Scott's pi assumes that any differences are due to chance.
Benefits:
Accounts for chance agreement.
Accounts for the number of categories and the distribution of values across them.
Accounts for differences in the distribution of values across categories for different coders.
Limitations - Krippendorff (2004) argues that Cohen’s Kappa should not be used to measure reliability in reliability analysis because:
It tends to overestimate agreement when working with imbalanced datasets, where one category is more prevalent than the others.
It assumes that coders are independent of each other, which is not always the case.
Rather than being independent, he suggests that coders should be interchangeable.
Formula:
p_o = Proportion of observed agreements
p_e = Proportion of expected agreements by chance
Kappa = (p_o - p_e) / (1 - p_e)
Krippendorff's alpha (a)
Krippendorff's alpha measures how well different coders agree when coding data at different levels of measurement, such as in surveys, journals, or research studies. For this reason, this technique is particularly useful in content analysis where data is often sourced from different formats. It can be used to account for chance agreements with any number of coders and is widely accepted in most research formats. The creator, Klaus Krippendorf, is considered a pioneer in the field of content analysis.
Benefits:
Accounts for chance agreement.
Allows for any number of coders.
Designed for variables at different levels of measurement from nominal to ratio.
Accounts and adjusts to imbalanced datasets.
Able to account for and adjust to missing data.
Limitations:
It is the most complex and time-intensive of these measurements.
Formula:
O = Observed disagreements
E = Expected disagreements
Alpha = 1 - (O / E)
[Continued readings: Read more about each measurement here. | Read more about the specific formulas here.]
2. Practice with a sample data set.
Have your researchers code the same section of a transcript and compare the results to see what the intercoder reliability is.
If the reliability is not sufficient, review, iterate, and learn from the experience. Do the exercise again until the reliability index is sufficient
3. Code your data
Do check-ins during the qualitative coding process to double-check whether or not your researchers are coding consistently. Make adjustments as necessary.
Calculate Intercoder Reliability On Delve
Delve automates intercoder reliability calculations, boosting efficiency and accuracy compared to manual calculations done by hand
To use the ICR feature, two or more researchers need to code the same transcript. The calculation automatically renders through Krippendorff's alpha on a scale of -1 to 1.
You can follow the simple steps below to calculate intercoder reliability using Delve.
Step 1: Create a project with a codebook.
Intercoder reliability measures how your team will apply the same codebook. So before you begin coding, you will need a codebook with well-defined code descriptions.
Step 2. Invite your team to the same project.
After creating the project with a codebook, invite your team to the project. You can invite them using the ‘Share’ button in the upper right-hand corner.
Step 3: Your team should code the transcript using the “Coded By Me” feature.
Your research team should code the same transcript without looking at each other's work. They can do that using the "Coded By Me" feature, which hides the work of all other team members.
Learn how to use the "Coded By Me" feature
⚠️ Note: As a team, you should agree if the coders can or cannot add more codes to the codebook. ICR is most appropriate for deductive coding exercises, where the team does not add new codes to the codebook.
Step 4: Calculate your intercoder reliability score.
🅐 To calculate ICR, use the Transcript Navigation Dropdown and click Coding Comparison.

🅑 There you will see a button for Inter Coder Reliability.

🅒 Clicking it will provide you with your intercoder reliability score for that transcript.
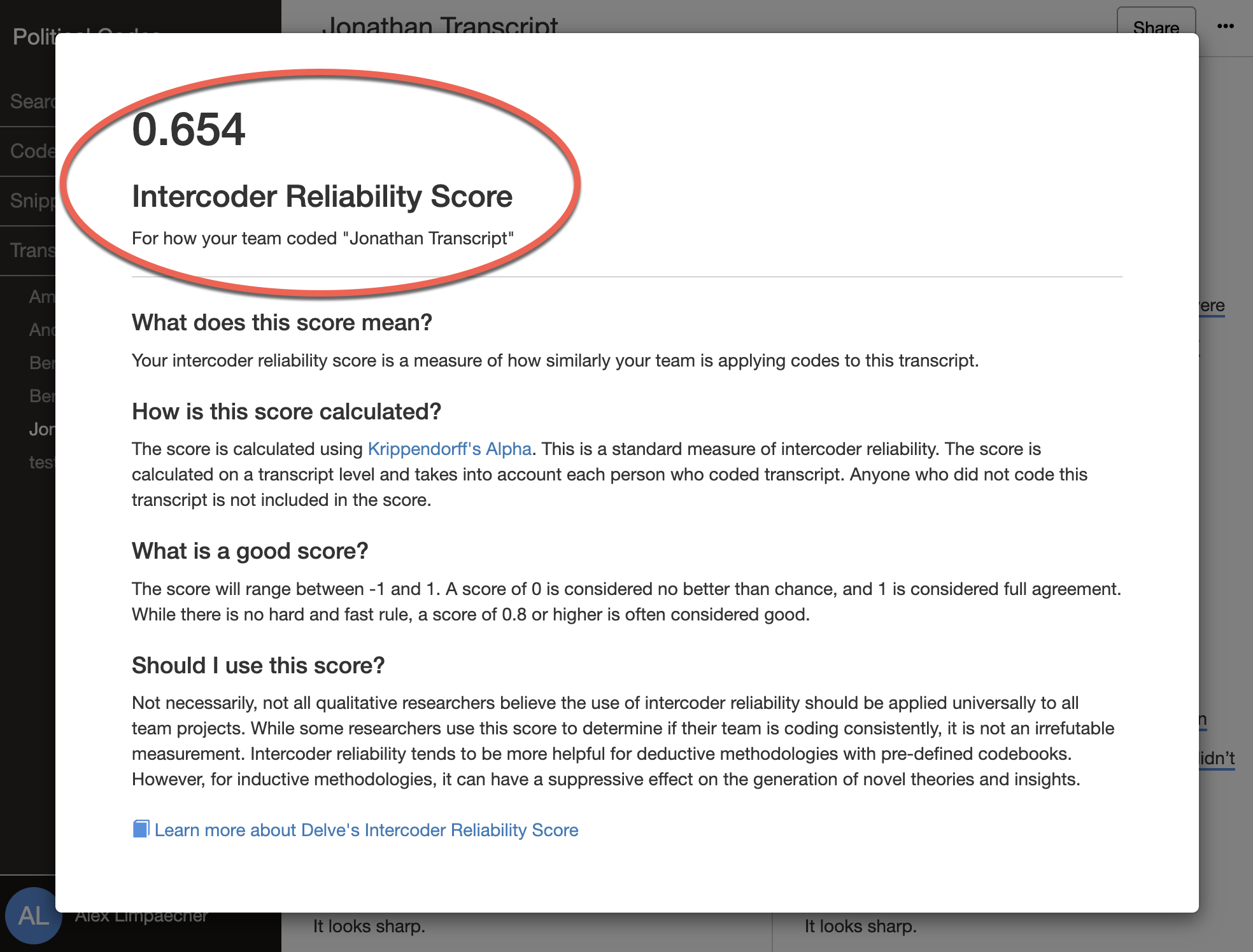
For more details on requirements, research scenarios to use Delve's Intercoder Reliability Score, and an explanation of the calculation process, please refer to this link.
Wrapping Up
Intercoder reliability measures how much co-researchers agree when using the same codebook on the same data. High ICR lets other researchers know they are likely to achieve the same results using the same codebook. This transferability acts as a signal of trustworthiness to other researchers.
Qualitative analysis doesn't have to be overwhelming
Take Delve's free online course to learn how to find themes and patterns in your qualitative data. Get started here.

Try Delve, Collaborative Software for Qualitative Coding
Online software such as Delve can help streamline how you’re coding your qualitative coding. Try a free trial or request a demo of the Delve.
References
Lombard, Matthew & Snyder-Duch, Jennifer & Bracken, Cheryl. (2005). Practical Resources for Assessing and Reporting Intercoder Reliability in Content Analysis Research Projects.
Richards, Lyn (2009). Handling Qualitative Data: A Practical Guide, 2nd edn. London: Sage.
Shenton, A. K. (2004). Strategies for Ensuring Trustworthiness in Qualitative Research Projects. Education for Information, 22, 63-75. https://doi.org/10.3233/EFI-2004-22201
Potter, W. James and Deborah Levine-Donnerstein. “Rethinking validity and reliability in content analysis.” Journal of Applied Communication Research 27 (1999): 258-284.
Klaus Krippendorff, Reliability in Content Analysis: Some Common Misconceptions and Recommendations, Human Communication Research, Volume 30, Issue 3, July 2004, Pages 411–433, https://doi.org/10.1111/j.1468-2958.2004.tb00738.x
Cite This Article
Delve, Ho, L., & Limpaecher, A. (2023c, April 26). Inter-coder reliability https://delvetool.com/blog/intercoder